Support Vector Machine
Introduction
Support Vector Machines (SVM) are a commonly used supervised learning model. First developed in the 1990’s at Bell Laboratories, SVMs can be used for either classification or regression analysis. SVMs work by maximizing the distance between two categories. When provided with new data, the model determines which cluster the new data is closest to and then outputs the identity of that cluster as the result.
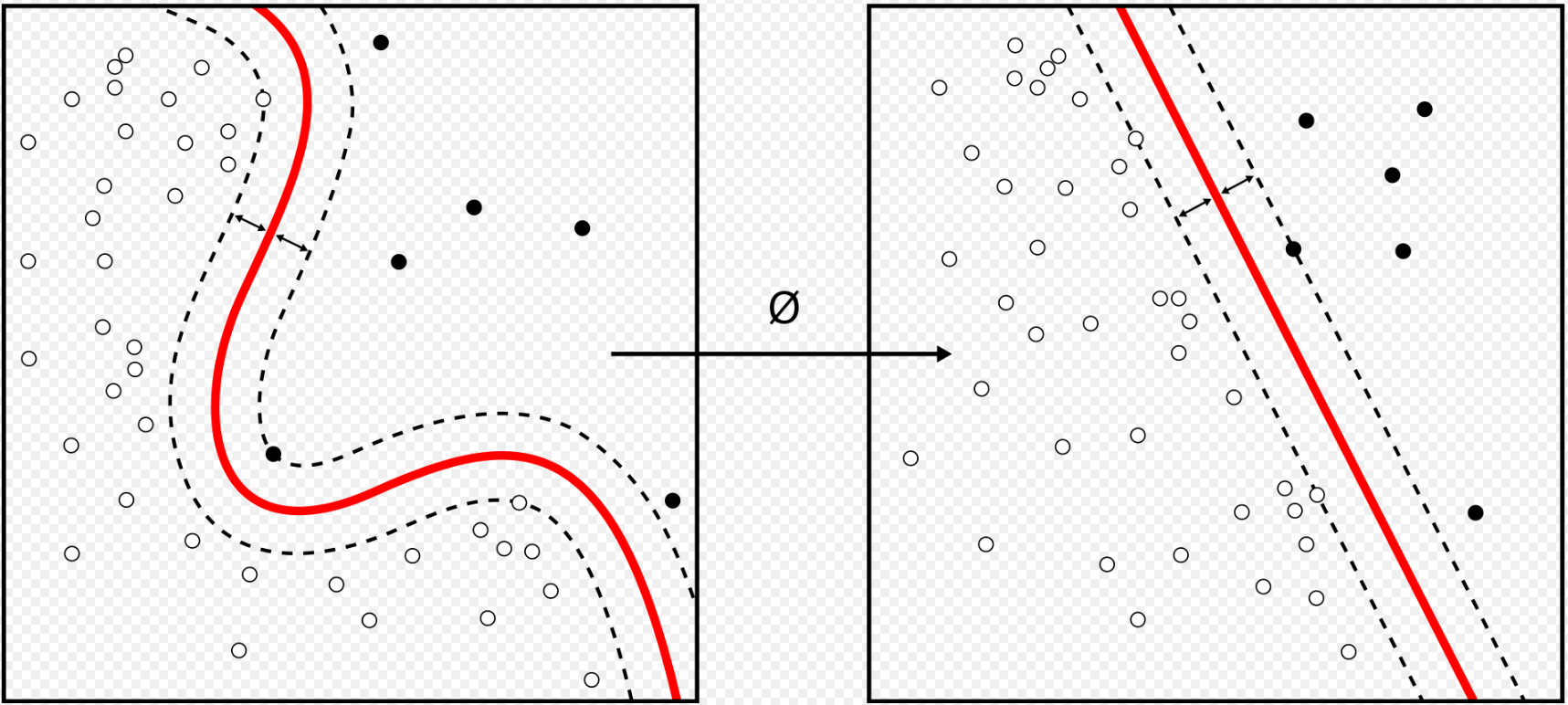
Source: https://en.wikipedia.org/wiki/Support_vector_machine#/media/File:Kernel_Machine.svg
Results
All Features Model
To train a SVM model on the drug use dataset, all categorial features were first transformed using the panadas get dummies function. Next, the data was split into training and testing sets. A standard scaler was trained using the training data set and used to scale the test and training datasets. Finally, a SVM model was trained using the sklearn.svm.SVC. The model had 80.8% accuracy when evaluated using the test dataset.
Personality Only Model
A second SMV model was created using only the personality score features. The same procedure was followed for pretreating the data and creating the model (pandas get dummies, standard scaler, sklearn.svm.SVC). The personality only model had an accuracy of 77.6% when evaluated using the test dataset.