Logistic Regression
Introduction
Logistic regression models are common in machine learning settings and are generally strong choices when dealing with binary target variables. In other words, if one wants to predict a yes/no, true/false, success/fail type outcomes, a logistic regression model might be an ideal place to start. This model can use few to many features to predict the target outcome. Additionally, feature variables can be either categorical or continuous in nature. Logistic regressions can also run relatively quickly and efficiently.
Image Source
A few examples of common use cases for the logistic regression model:
- Predicting the presence of a specific disease or disorder based on a patient’s symptoms
- Determining whether an individual is a risk to default on a credit card based on their financial profile
- Estimating a voter’s likely candidate preference in a political election
Image Source
Results
Our models were generated using the scikit-learn package for Python. The preprocessed version of our data was imported and categorical columns were encoded in order to simplify our dataset, mainly for the utilization of other model types.
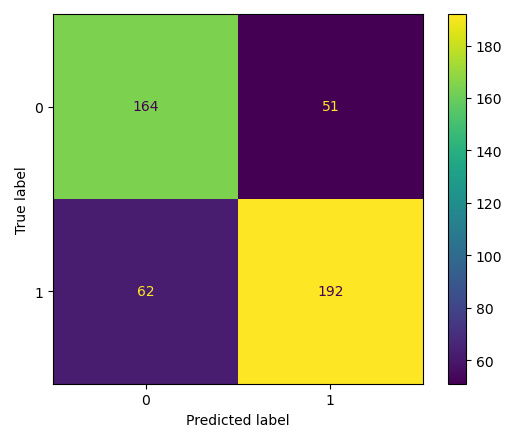
All Features Model
For our first iteration of the logistic regression model, we tested our data as it was without making any tweaks and including all feature variables. This produced a favorable result as a preliminary model, producing over 80% accuracy on both the training and testing data:

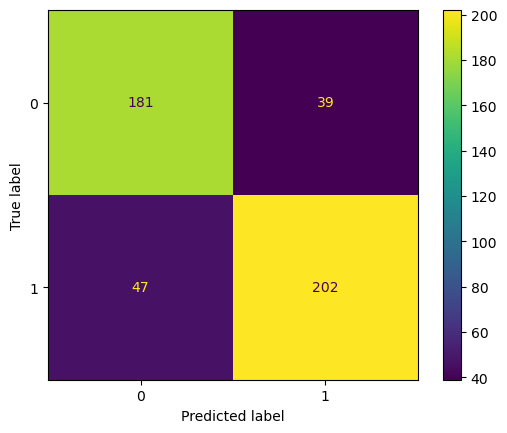
Personality Features Only
Since the personality characteristic variables were of notable interest for our group, we decided to test our logistic regression model out once again, but the personality variables were the only features of the tested data. All the demographic information was removed in order to get a more direct answer to whether these personality attributes serve as predictors to illegal drug use. Here are the results of this iteration:

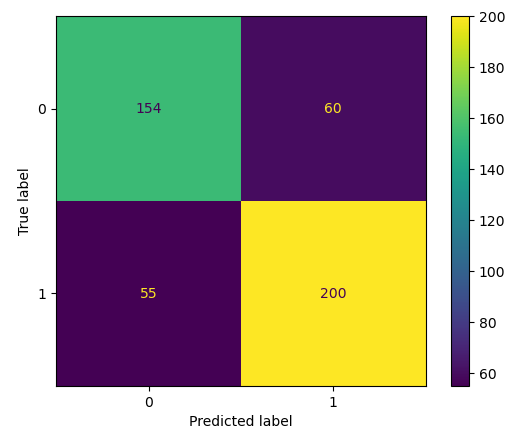
PCA Feature Reduction
Bringing all features back into the mix since the personality only version performed slightly poorer, we tried to reduce features using PCA. We set our feature reduction to account for 90% of our data’s variance and it reduced our 37 columns down to 13 new features. With these features, we ran our model once again to see if this would improve the scores: